Recentemente, enfrentei um desafio que, à primeira vista, parecia simples: importar uma grande quantidade de dados em um banco MySQL. No entanto, o volume total ultrapassava 19 milhões de linhas distribuídas em diversos arquivos CSV. Ferramentas tradicionais como o Workbench ou DBeaver simplesmente travavam — fosse por causa do tamanho do arquivo, do uso excessivo de RAM ou da ausência de controle de progresso. Foi nesse contexto que nasceu o Cargueiro, um sistema que projetei e construí com ajuda de vibe coding para lidar com grandes cargas de dados de forma estável, eficiente e visualmente transparente.
Entendendo o problema
O primeiro obstáculo era o tamanho dos arquivos. Algumas planilhas tinham mais de 5 GB, o que fazia qualquer ferramenta engasgar. Além disso, não havia feedback visual sobre o progresso: uma vez iniciado o upload, eu só podia cruzar os dedos. Se algo falhasse, não havia opção de retomar de onde parou — era necessário recomeçar tudo do zero. Para completar, em casos de duplicação de dados, o comportamento dos sistemas era imprevisível.
Tudo isso me levou a pensar: “Será que consigo construir minha própria solução, só que do meu jeito?”.
O papel do vibe coding
Foi aí que o vibe coding entrou em cena. Essa prática consiste em usar um modelo de linguagem como parceiro de programação: você descreve o que precisa, ele gera sugestões, você testa e vai refinando por meio do diálogo.

Comecei com uma ideia simples: construir um sistema web que permitisse o upload de arquivos CSV, dividisse automaticamente o conteúdo em partes menores, e inserisse os dados no banco MySQL com controle de progresso e capacidade de retomar após falhas. A cada passo, descrevia a tarefa para o modelo: “Crie uma função que leia um CSV em pedaços de 10 mil linhas”, ou “Como faço para registrar o progresso da importação em um arquivo de log?”.
Esse processo iterativo, quase como um pair programming com inteligência artificial, se mostrou incrivelmente produtivo. Em poucos dias, o Cargueiro estava em funcionamento.
Arquitetura do sistema
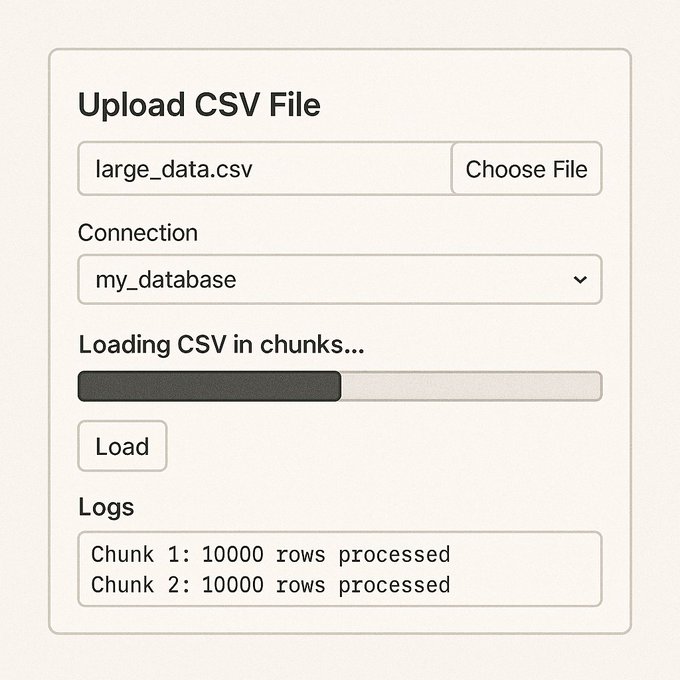
O Cargueiro tem uma estrutura simples, mas robusta. O frontend foi construído com Tailwind CSS puro, com uma interface leve e intuitiva — apenas o necessário: um formulário de upload, uma barra de progresso e uma área para logs. Nada de bibliotecas pesadas.
No backend, usei FastAPI com rotas síncronas que acionam threads para não bloquear a aplicação. O CSV é processado em blocos de 10 mil linhas, e cada bloco é inserido no banco via SQLAlchemy. A cada lote processado, o sistema atualiza um arquivo progresso.log, que é lido constantemente pelo frontend para atualizar a barra de progresso em tempo real.
E o melhor: se houver alguma falha, o sistema verifica até onde foi e continua a partir do ponto interrompido, evitando retrabalho.
Soluções inteligentes para problemas reais
Alguns recursos do Cargueiro foram pensados exatamente para evitar os traumas das ferramentas tradicionais:
- Chunking: Ao dividir os dados em pedaços menores, evitamos transações grandes demais e o risco de falhas massivas.
- Controle de duplicação: Utilizo comandos SQL com ON DUPLICATE KEY UPDATE para lidar com registros já existentes, sem interromper o processo.
- Feedback visual: A interface mostra claramente quantas linhas já foram processadas e se há erros.
- Retomada automática: Em caso de erro, o sistema recomeça do último ponto salvo no log, sem precisar reiniciar o upload.
Resultados alcançados
Depois que o Cargueiro ficou pronto, consegui importar os 19 milhões de registros em apenas 3 dias, com uso de memória inferior a 1 GB. Não houve nenhuma falha crítica, e a capacidade de retomada me salvou pelo menos duas vezes.
Além disso, qualquer pessoa, mesmo sem conhecimento técnico, consegue utilizar a ferramenta. Basta escolher o arquivo CSV, selecionar a conexão e iniciar o processo. Simples assim.

O que aprendi
Trabalhar com vibe coding me permitiu transformar um problema frustrante em uma oportunidade de aprendizado. Construí um sistema útil, estável e adaptável em tempo recorde, guiado por uma abordagem conversacional que favorece o raciocínio em blocos e a validação contínua.
No final das contas, o Cargueiro não é apenas uma ferramenta de carga de dados. É um exemplo prático de como podemos usar inteligência artificial para ampliar nossa capacidade de criação — mesmo em tarefas extremamente técnicas.
Se você já enfrentou dificuldades para inserir grandes volumes de dados em um banco, recomendo fortemente experimentar esse tipo de abordagem. E se quiser trocar ideias ou acompanhar o projeto, fique à vontade para comentar ou seguir as atualizações futuras.
Caso queira dar uma olhada no código, seguei ai:
https://github.com/elzobrito/Cargueiro
Até breve! — Elzo Brito