Se você já usou um chatbot ou assistente de código e ficou impressionado com a rapidez das respostas — ou, pelo contrário, irritado com a lentidão de um modelo gigante — saiba que por trás dessas experiências há um desafio técnico significativo: como tornar a inferência de LLMs (Modelos de Linguagem de Grande Escala) mais eficiente? É aqui que entra o projeto VLLM, uma iniciativa open source nascida em Berkeley com o objetivo de otimizar o uso de memória e reduzir a latência na execução desses modelos.
O Problema: LLMs São Custosos e Lentos
Rodar um modelo de linguagem não é como rodar uma planilha ou um sistema tradicional. Cada palavra gerada exige cálculos pesados. Quando você executa um LLM numa máquina virtual ou em Kubernetes, está lidando com consumo intenso de GPU, gargalos de memória e latência em lote. Isso significa que as empresas muitas vezes precisam investir em hardware caro — não por necessidade real de processamento, mas por ineficiências no uso da GPU.
Outro ponto crítico é a escalabilidade. Servir um modelo para muitos usuários simultaneamente frequentemente ultrapassa a capacidade de uma única GPU, exigindo arquiteturas distribuídas complexas que são caras e difíceis de manter.
A Solução: O Que é o VLLM?
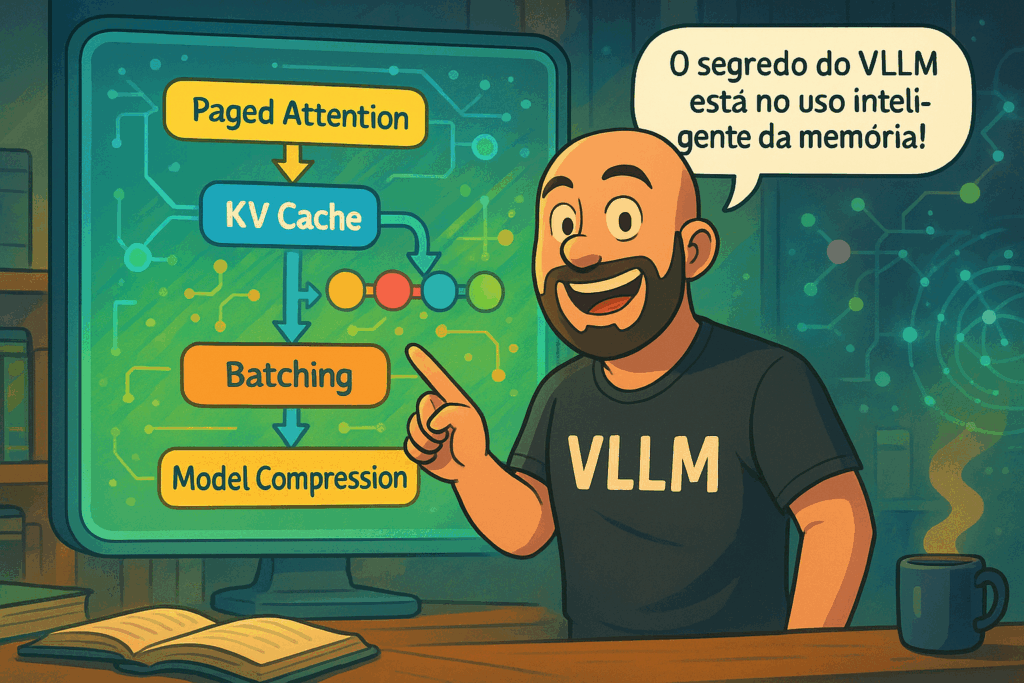
O VLLM (Virtual Layered Language Model) surge como resposta a esses desafios. Ele oferece uma forma mais inteligente de gerenciar a memória da GPU e processar solicitações com mais eficiência. Seu grande trunfo está no algoritmo Paged Attention, que quebra a memória contínua em páginas, como se fosse a RAM virtual de um sistema operacional. Assim, o modelo só carrega na GPU o que realmente precisa naquele momento.
Além disso, o VLLM usa uma técnica chamada Continuous Batching, que preenche os slots de GPU de forma dinâmica à medida que sequências anteriores são completadas. Isso elimina o tempo ocioso típico em pipelines sequenciais, melhorando drasticamente o throughput.
Por Que Ele Está Ganhando Popularidade?
Nos benchmarks iniciais, o VLLM mostrou um aumento de 24x no desempenho comparado com ferramentas como Hugging Face Transformers e TGI (Text Generation Inference). Ele é compatível com diversos modelos populares — como LLaMA, Mistral e Granite — e suporta quantização, chamadas de ferramentas (tool calling) e otimizações específicas para drivers CUDA.
A instalação é simples via pip install, e o VLLM oferece um endpoint compatível com a API da OpenAI. Isso significa que aplicações que já usam OpenAI podem migrar para um modelo local servido com VLLM sem grandes alterações no código.
Quando Usar o VLLM?
Se você trabalha com modelos localmente ou precisa atender múltiplos usuários com respostas rápidas e custo controlado, o VLLM pode ser a ferramenta ideal. Ele foi pensado para ambientes Linux, incluindo clusters Kubernetes, e oferece vantagens especialmente para modelos quantizados, ajudando a manter precisão com menos uso de recursos.